A systematic review is a rigorous, reproducible method of identifying, evaluating, and synthesizing all available evidence on a clearly defined research question. It differs from a narrative review by using pre-specified eligibility criteria, comprehensive database searching, dual independent screening, formal risk-of-bias assessment, and structured data synthesis — all documented transparently so the process can be replicated. A full systematic review typically takes 12–24 months and requires a minimum team of three people. The core steps are: formulate the PICO question → register the protocol (PROSPERO) → design and run the search → screen titles and abstracts → full-text screening → data extraction → quality assessment → synthesis (with or without meta-analysis) → GRADE the evidence → report using PRISMA.
What No One Tells You Before You Start
Here is the first thing every systematic review guide skips: this will take longer than you think, cost more than you budgeted, and require people you haven’t recruited yet.
A full systematic review averages 1,000–2,000 person-hours across its lifecycle. It takes 12–24 months from protocol registration to publication. The literature search alone — when designed properly with a research librarian — takes 2–6 weeks. Title and abstract screening for a large review can occupy a team of three for three to six months. And the entire process must begin again if your search strategy has a significant gap.
Most guides present systematic reviews as a clean, sequential checklist. The reality is a recursive, iterative, and occasionally demoralizing process that rewards preparation, punishes shortcuts, and produces genuinely important knowledge when done right.
This guide gives you the full picture — the methodology, the modern AI-assisted workflow, the common mistakes that cause rejection, and the things the textbooks quietly omit.
What Is a Systematic Review?
A systematic review is a type of literature review that uses explicit, pre-specified methods to identify, select, critically appraise, and synthesize all relevant evidence on a specific research question.
The word “systematic” carries real meaning here. It refers not to the topic but to the method: every decision in a systematic review — which databases to search, which studies to include, how to assess quality, how to handle disagreement between reviewers — is made in advance, documented in a protocol, and applied consistently throughout. This systematization is what separates a systematic review from an expert opinion, a narrative review, or a selective summary of convenient evidence.
Why it matters: Individual studies are subject to chance variation, small sample sizes, and local context. A well-conducted systematic review aggregates the best available evidence across all qualifying studies, producing a more reliable estimate of truth than any single study can offer. It sits at or near the top of the evidence hierarchy in healthcare, public policy, education, and social science research.
Epidemiologist Archie Cochrane formalized systematic review methodology in the 1970s, arguing that medicine needed to organize its evidence into reliable summaries that clinicians could actually use. The Cochrane Collaboration — now the world’s largest producer of systematic reviews — carries his name.
Systematic Review vs. Every Other Review Type: Which One Do You Actually Need?
One of the most common and costly mistakes researchers make is choosing the wrong review type. Starting a full systematic review when a scoping review was appropriate wastes a year of work. Conducting a rapid review when the evidence base demands rigorous synthesis can mislead policy decisions.
Here is the decision framework that every guide should include but doesn’t.
| Review Type | Best Used When | Team Size | Typical Duration | Meta-Analysis? |
|---|---|---|---|---|
| Systematic review | You need to establish causal effectiveness of an intervention | 3–8 people | 12–24 months | Often yes |
| Scoping review | You want to map the breadth of a field, identify gaps, or clarify concepts | 2–4 people | 4–12 months | No |
| Rapid review | A decision-maker needs evidence within weeks, not years | 2–3 people | 4–12 weeks | Sometimes |
| Umbrella review | You want to synthesize existing systematic reviews (not primary studies) | 2–4 people | 6–12 months | Sometimes |
| Realist review | You want to understand how and why an intervention works, not just if it works | 3–5 people | 12–18 months | No |
| Integrative review | You want to include diverse study designs and methodologies | 2–4 people | 6–18 months | Rarely |
| Network meta-analysis | You need to compare multiple interventions simultaneously, including indirect comparisons | 3–6 people + statistician | 12–24 months | Yes (advanced) |
| Meta-ethnography | You want to synthesize qualitative research findings | 2–4 people | 12–18 months | No |
The decision rule: If your question is “Does intervention X improve outcome Y compared to control Z in population P?” — you need a systematic review or meta-analysis. If your question is “What does the evidence landscape look like on topic T?” — you need a scoping review. If you need an answer within six weeks — you need a rapid review, with transparent acknowledgment of its limitations.
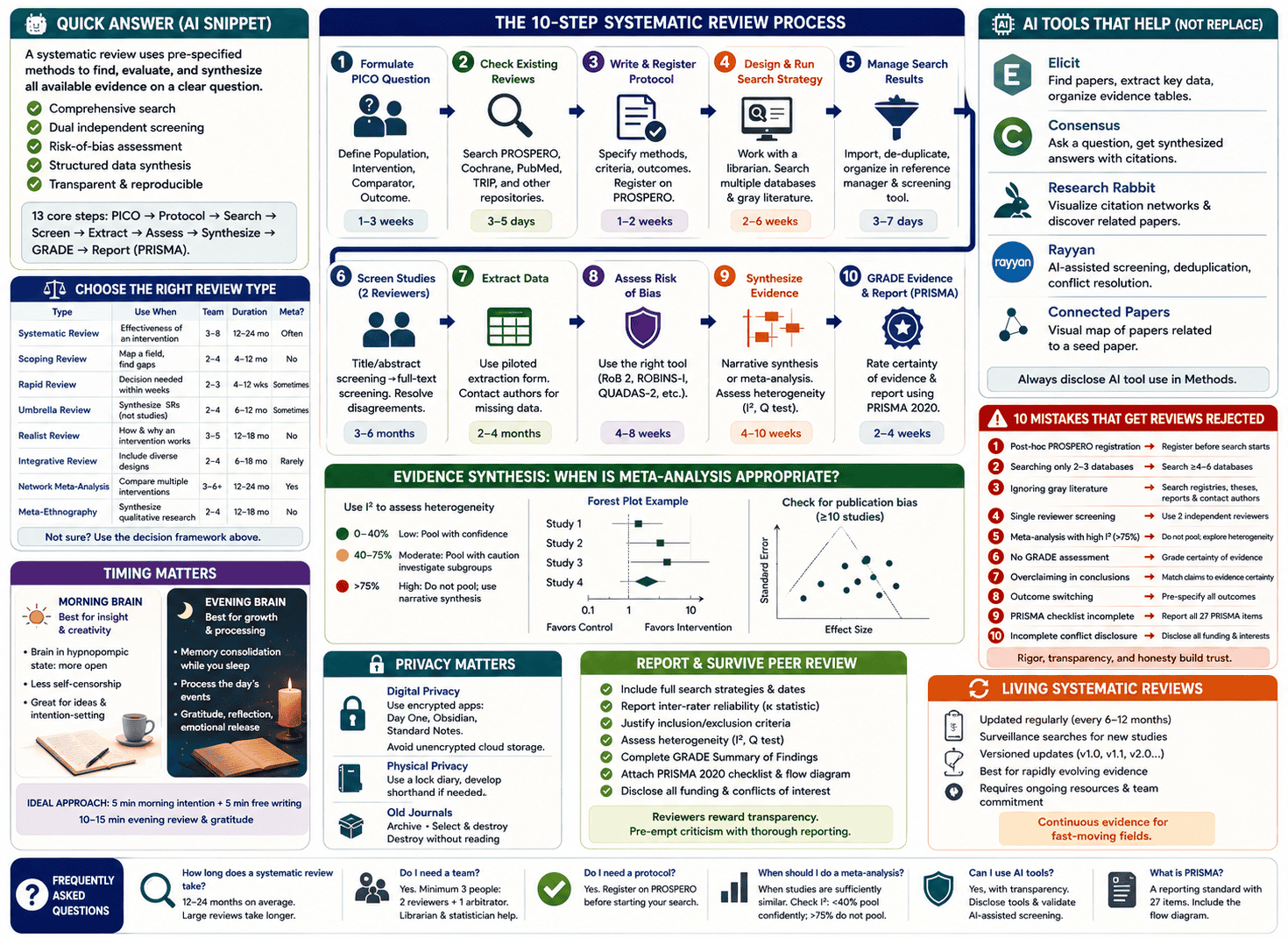
The 10-Step Systematic Review Process (With Honest Time Estimates)
Step 1: Formulate Your Research Question Using PICO
Every systematic review begins with a precisely structured research question. Vague questions produce unmanageable reviews. The PICO framework forces precision:
- P — Population: Who are the participants? (e.g., adults aged 18–65 with type 2 diabetes)
- I — Intervention: What is being done? (e.g., intensive lifestyle modification)
- C — Comparator: What is it being compared against? (e.g., standard care)
- O — Outcome: What are you measuring? (e.g., HbA1c reduction at 12 months)
For non-intervention questions, alternative frameworks apply: PEO (Population, Exposure, Outcome) for observational studies, SPIDER (Sample, Phenomenon of Interest, Design, Evaluation, Research type) for qualitative reviews, and SPICE (Setting, Perspective, Intervention, Comparison, Evaluation) for health services research.
Time estimate: 1–3 weeks. Do not rush this step. A PICO that is too broad generates thousands of irretrievably irrelevant results. A PICO that is too narrow misses studies that should have been included. Both errors contaminate everything downstream.
The test of a good PICO: You can state your research question in a single sentence, and two colleagues independently interpret it the same way.
Step 2: Check for Existing Reviews and Validate Your Question
Before investing months in a review, confirm that you are not duplicating one already published or currently in progress. Search:
- Cochrane Library — the definitive repository of completed and ongoing Cochrane systematic reviews
- PROSPERO — the international register of ongoing systematic reviews (University of York / NIHR)
- Campbell Collaboration — systematic reviews in social science, education, and international development
- PubMed — filter by publication type “Systematic Review”
- TRIP Database — evidence-based synthesis and guideline database
If an existing review addresses your question well, consider whether your review would offer genuine added value — a more recent search, a different population, a different outcome measure, or a corrected methodological flaw in the existing review.
Time estimate: 3–5 days.
Step 3: Write and Register Your Protocol
A protocol is your pre-registered plan — written before you see the results. It specifies your research question, eligibility criteria, databases, search strategy, screening process, data extraction plan, quality assessment tools, and synthesis approach.
Why registration matters: Registering your protocol on PROSPERO before data collection begins serves three critical functions. First, it establishes a public record that prevents you from unconsciously shifting your outcomes after seeing the data (outcome switching — a form of bias). Second, it prevents duplication — other researchers can see that your review is underway. Third, it is increasingly required by journals as a condition of peer review.
PROSPERO registration in practice:
- Create an account at prospero.york.ac.uk
- Complete all mandatory fields, including the review question, eligibility criteria, and anticipated search strategy
- Have your principal investigator review the entry before submission
- PROSPERO assigns a registration number (CRN) — include this in every manuscript submission
The critical rule: Register before you begin your literature search. Post-hoc registration is a red flag to peer reviewers and signals the possibility of outcome switching.
Time estimate: 1–2 weeks to write a thorough protocol.
Step 4: Design and Execute the Search Strategy
The literature search is the most technically demanding step in the entire process — and the one most often executed poorly by researchers without library science training.
Work with a research librarian. This is not optional. A trained systematic review librarian understands Boolean operators, database-specific syntax (MeSH terms in PubMed, Emtree in Embase, thesaurus terms in CINAHL), proximity operators, and how to avoid the two types of search error: retrieving too little (missing relevant studies) and retrieving too much (creating an unmanageable screening burden).
The minimum database set for a healthcare systematic review:
- MEDLINE/PubMed
- Embase
- Cochrane Central Register of Controlled Trials (CENTRAL)
- CINAHL (for nursing and allied health)
- PsycINFO (for psychological outcomes)
- A discipline-specific database relevant to your topic
Gray literature — the sources most reviews miss:
Searching only peer-reviewed databases introduces publication bias: studies with positive findings are more likely to be published, and published in English, than studies with neutral or negative findings. A systematic review that ignores gray literature systematically overestimates treatment effects.
Gray literature sources to search systematically:
- Trial registries: ClinicalTrials.gov, WHO International Clinical Trials Registry Platform (ICTRP)
- Theses and dissertations: ProQuest Dissertations, EThOS (UK), DART-Europe
- Government and agency reports: NICE, WHO, FDA, relevant national health agencies
- Conference proceedings: Relevant conference abstract books, often searchable in Embase
- Unpublished data: Contact corresponding authors of included studies for unreported outcomes
Language bias: Studies demonstrate that trials with statistically significant results are approximately 1.5–2 times more likely to be published in English than non-significant trials. English-only searches therefore bias pooled estimates toward positive effects. The decision to exclude non-English studies should be explicitly stated and justified — not made silently.
Time estimate: 2–6 weeks for search design, strategy review by a second librarian (a peer-review of search strategy, or PRESS review), and execution across all databases.
Step 5: Manage Search Results
Your searches will return anywhere from hundreds to tens of thousands of records. Before screening begins, you must:
- Import all results into a reference manager (Endnote, Zotero, Mendeley)
- De-duplicate records — the same study often appears in multiple databases
- Import the de-duplicated library into your systematic review screening software
Key tools:
- Endnote / Zotero / Mendeley — reference management and de-duplication
- Covidence — the most widely adopted screening and data extraction platform; PRISMA-compatible; used by Cochrane
- Rayyan — free collaborative screening tool with AI-assisted deduplication and suggestion features
- DistillerSR — enterprise-grade systematic review platform with automation features for large teams
- EPPI-Reviewer — used by the EPPI-Centre for complex mixed-method reviews
Time estimate: 3–7 days for de-duplication and import setup.
Step 6: Screen Studies (Two Independent Reviewers, Always)
Screening happens in two phases:
Phase 1 — Title and abstract screening: Each record is reviewed against your pre-defined inclusion and exclusion criteria. Records are marked include, exclude, or uncertain. At least two independent reviewers screen all records. Disagreements go to a third reviewer or are resolved by consensus discussion.
Phase 2 — Full-text screening: The full text of all records that passed Phase 1 is retrieved and assessed against the complete eligibility criteria. Reasons for exclusion at this stage must be documented — PRISMA requires you to report them.
Inter-rater reliability: Calculate Cohen’s kappa or percentage agreement before beginning full-scale screening. A kappa below 0.6 indicates insufficient agreement in how reviewers are applying the criteria — resolve through calibration before proceeding. This is a step that most guides mention once and then never explain.
Pilot your criteria: Before screening the full set, both reviewers independently screen the same 50 records and compare results. If agreement is poor, your criteria need clarification.
Time estimate: 3–6 months for a large review with thousands of records.
Step 7: Extract Data From Included Studies
Data extraction is the process of systematically pulling all relevant information from each included study into a standardized form. This includes:
- Study characteristics: authors, year, country, design, sample size, setting
- Population characteristics: demographics, inclusion/exclusion criteria applied
- Intervention details: dose, duration, delivery method, comparator
- Outcome data: means, standard deviations, event rates, confidence intervals, p-values
- Funding source and conflicts of interest
Use a piloted data extraction form. Build the form in Covidence, DistillerSR, or a structured spreadsheet. Pilot it on three to five studies with all extractors independently, then compare and resolve discrepancies before full extraction begins.
Contact authors for missing data. When key outcome data are not reported in a paper, contact the corresponding author directly. Many authors retain unpublished datasets and will share them for inclusion in a systematic review.
Time estimate: 2–4 months depending on the number of included studies and complexity of data.
Step 8: Assess Risk of Bias in Each Included Study
Risk of bias assessment evaluates the methodological quality of each included study — specifically, whether flaws in design, conduct, or reporting could have systematically distorted the results in one direction.
The right tool depends on the study design:
- RCTs: Cochrane Risk of Bias Tool 2 (RoB 2) — assesses five domains: randomization process, deviations from intended intervention, missing outcome data, measurement of the outcome, and selection of the reported result
- Non-randomized studies: ROBINS-I (Risk Of Bias In Non-randomized Studies of Interventions)
- Observational studies: Newcastle-Ottawa Scale or CASP checklists
- Diagnostic test accuracy studies: QUADAS-2
- Qualitative studies: CASP Qualitative Checklist
- Systematic reviews (for umbrella reviews): AMSTAR 2
How to interpret risk of bias: A study rated “high risk of bias” in a critical domain does not automatically get excluded from the review. It does, however, affect how much weight its results carry in your synthesis and conclusions, and it directly affects the GRADE certainty rating of the evidence.
Time estimate: 4–8 weeks for a thorough assessment of all included studies.
Step 9: Synthesize the Evidence — With or Without Meta-Analysis
Data synthesis answers the review question by combining findings across included studies. Two approaches exist:
Narrative synthesis: Describe and compare study findings in structured text tables, without statistically pooling the results. Use when studies are too heterogeneous in population, intervention, or outcome to meaningfully combine numerically.
Meta-analysis: Pool quantitative results from multiple studies using statistical methods (typically weighted mean difference or standardized mean difference for continuous outcomes; odds ratio or risk ratio for binary outcomes) to produce a single summary estimate with a confidence interval, displayed in a forest plot.
The critical question before running a meta-analysis: is pooling appropriate?
This is where most systematic reviews make a serious error. Researchers pool data because they have it — not because it is statistically appropriate to combine it. The tool for assessing whether pooling is appropriate is the I² statistic, which measures the percentage of total variation across studies that is attributable to genuine heterogeneity rather than sampling error.
Interpreting I²:
- 0–40%: Low heterogeneity — pooling is generally appropriate
- 40–75%: Moderate heterogeneity — pooling with caution; investigate sources of heterogeneity via subgroup analysis
- >75%: Substantial heterogeneity — pooling is usually inappropriate; narrative synthesis with subgroup analysis is preferable
Cochran’s Q test provides a formal statistical test of heterogeneity (though it has low power with few studies). Use I² and Cochran’s Q together, alongside clinical judgment about whether studies are sufficiently similar in population, intervention, and outcome to make pooling meaningful.
When I² is high, investigate — don’t ignore. Subgroup analyses by study design, population age, intervention dose, or follow-up duration often explain the source of heterogeneity and reveal important insights about where and for whom an intervention works.
Publication bias: When you have 10 or more studies in a meta-analysis, assess for publication bias using a funnel plot and Egger’s test. Asymmetry in the funnel plot suggests that small, non-significant studies are missing — probably unpublished — which inflates the apparent effect size.
Time estimate: 4–10 weeks for synthesis and meta-analysis, including statistical verification.
Step 10: Grade the Evidence and Report Using PRISMA
GRADE (Grading of Recommendations Assessment, Development and Evaluation) is the framework for rating the certainty of your evidence — and it is mandatory for Cochrane reviews, expected by most major journals, and entirely absent from most systematic review guides.
GRADE rates evidence certainty across four levels:
| Certainty Level | Meaning | Typical Starting Point |
|---|---|---|
| High | We are very confident the true effect lies close to the estimated effect | RCTs with low risk of bias |
| Moderate | We are moderately confident in the effect estimate; the true effect is likely close but may differ | RCTs with some limitations, or upgraded observational studies |
| Low | Our confidence is limited; the true effect may differ substantially from the estimate | RCTs with serious limitations, or observational studies |
| Very low | We have very little confidence in the effect estimate | Highly flawed evidence of any type |
Five factors that can downgrade certainty:
- Risk of bias (methodological limitations in included studies)
- Inconsistency (unexplained heterogeneity in results across studies)
- Indirectness (the evidence applies to a different population, intervention, or outcome than the review question)
- Imprecision (wide confidence intervals; small total sample size)
- Publication bias (evidence of selective non-reporting)
Three factors that can upgrade certainty (for observational evidence):
- Large magnitude of effect (OR > 2 or < 0.5 is rarely fully explained by bias)
- Dose-response gradient
- All plausible confounders would reduce the apparent effect
PRISMA reporting: Complete the PRISMA 2020 checklist (27 items) and include the PRISMA flow diagram showing the number of records identified, screened, assessed for eligibility, and included. The PRISMA statement is available at prisma-statement.org. PRISMA extensions exist for specific review types: PRISMA-S (search reporting), PRISMA-NMA (network meta-analysis), PRISMA-Harms, PRISMA-Equity, and PRISMA-ScR (scoping reviews).
Time estimate: 2–4 weeks for GRADE assessment and PRISMA completion.
AI Tools That Are Changing Systematic Reviews Right Now
This is the section that did not exist three years ago and now defines the frontier of evidence synthesis methodology. AI tools do not replace rigorous systematic review methodology — but they meaningfully accelerate the most time-consuming phases.
Elicit
Primary function: AI-assisted literature search, screening, and data extraction
Elicit uses large language models to find relevant papers, extract key data points (population, intervention, outcome, study design, sample size) directly from abstracts and full texts, and organize findings in structured tables. It is particularly powerful for the early scoping phase, reducing the time needed to understand what a literature base contains before designing a formal search strategy.
Limitation: Elicit’s coverage is primarily limited to papers indexed in Semantic Scholar. It should supplement — not replace — comprehensive database searches in MEDLINE, Embase, and CENTRAL.
PRISMA-compatible: Use Elicit for scoping and preliminary data extraction; document its use transparently in your methods section.
Consensus
Primary function: Semantic search for scientific consensus across studies
Consensus allows natural language questions and returns synthesized answers drawn from peer-reviewed literature, with citations. It is useful for rapid landscape assessment — understanding the general state of evidence before committing to a full review — and for quickly identifying key papers to anchor your formal search.
Best use case: Initial question validation and identifying landmark studies to include in your MEDLINE search strategy as seed articles.
Research Rabbit
Primary function: Citation network mapping and literature discovery
Research Rabbit visualizes the citation relationships between papers — who cited whom, what papers co-cite the same foundational work, and which recent papers are most closely related to your key seed studies. It surfaces relevant literature that keyword searches in databases would miss, particularly older seminal papers and very recent preprints.
Best use case: Supplementary handsearching and citation chaining, which PRISMA requires as part of a comprehensive search.
Rayyan
Primary function: Collaborative screening with AI suggestion features
Rayyan is a free web-based screening platform with AI-assisted deduplication and a suggestion engine that learns from reviewer decisions and highlights potentially relevant records. It supports blinded dual-reviewer screening with a conflict resolution workflow and generates a PRISMA-compatible record of decisions.
Best use case: Title and abstract screening, particularly for teams screening thousands of records.
Connected Papers
Primary function: Visual literature mapping
Connected Papers generates a visual graph of papers related to a seed paper, weighted by similarity. It is excellent for identifying the most influential papers in an area and understanding how the literature is structured, but should be treated as a supplementary discovery tool rather than a primary search source.
Important Note on AI Tools and PRISMA Compliance
AI-assisted tools accelerate the review process but introduce their own methodological requirements. Every AI tool used in the review must be named, described, and justified in your methods section. The limitations of each tool — coverage gaps, potential algorithmic bias, lack of reproducibility in some cases — must be acknowledged. Peer reviewers at major journals are increasingly asking authors to justify their use of AI screening tools with validation data (e.g., sensitivity and specificity of AI screening against human screening on a sample).
10 Mistakes That Get Systematic Reviews Rejected (and How to Avoid Each One)
These are the specific, documented errors that lead to desk rejection, peer reviewer criticism, retraction requests, and years of wasted work.
Mistake 1: Post-Hoc PROSPERO Registration
The error: Registering your protocol on PROSPERO after you have already started — or completed — your literature search.
Why it matters: Post-hoc registration cannot prevent outcome switching, which is the reason registration exists. Peer reviewers cross-check registration dates against submission dates. A registration date after the search was conducted signals potential bias, even if none occurred.
The fix: Register before your search begins. If the registration is unavoidably late, disclose the delay explicitly and explain why it did not affect your protocol.
Mistake 2: Searching Only Two or Three Databases
The error: Running searches only in PubMed and one other database, then claiming comprehensiveness.
Why it matters: Different databases index different journals and time periods. A search limited to PubMed alone misses approximately 30–50% of relevant records for most clinical questions, depending on the field.
The fix: Search a minimum of four to six databases relevant to your topic, supplemented by gray literature and citation chaining. Document every database, the search date, and the number of records retrieved.
Mistake 3: Ignoring Gray Literature
The error: Searching only peer-reviewed databases and making no attempt to identify unpublished studies, trial registry records, or government reports.
Why it matters: Publication bias is real and quantifiable. Studies with positive findings are published at higher rates and more quickly than null or negative findings. Ignoring gray literature inflates your summary effect estimate.
The fix: Search ClinicalTrials.gov, WHO ICTRP, relevant gray literature repositories, and dissertation databases. Contact authors of included studies to ask about unpublished data.
Mistake 4: Single Reviewer Screening
The error: Having one person screen all titles, abstracts, and full texts to save time.
Why it matters: Single screening introduces individual bias and increases the risk of relevant studies being missed. PRISMA, Cochrane, and virtually every major journal require dual independent screening with documented inter-rater reliability.
The fix: Two reviewers independently screen all records. Calculate and report kappa at each stage. Resolve disagreements by consensus or through a third reviewer.
Mistake 5: Running a Meta-Analysis Despite High Heterogeneity
The error: Pooling results statistically when I² is above 75% because the software makes it easy.
Why it matters: Pooling incompatible studies produces a summary estimate that is statistically precise but clinically meaningless. It misrepresents what the evidence actually shows.
The fix: Calculate I² before deciding to pool. When heterogeneity is substantial, use narrative synthesis, investigate the sources of heterogeneity through subgroup analysis, and explain in the manuscript why pooling was not performed.
Mistake 6: No GRADE Assessment
The error: Reporting what the evidence shows without grading how certain we are that the evidence is correct.
Why it matters: A systematic review that finds a positive effect from three small RCTs with high risk of bias should not produce the same level of confidence as one drawing on ten large, low-bias RCTs. GRADE makes that distinction explicit. Cochrane requires it; most major journals expect it.
The fix: Complete a GRADE Summary of Findings table for each primary outcome. Use the GRADEpro GDT software (free at gradepro.org).
Mistake 7: Overclaiming in the Conclusions
The error: Concluding that “X intervention is effective for Y condition” when the evidence is low or very low certainty.
Why it matters: Conclusions that exceed the evidence quality mislead clinicians, policymakers, and guideline developers who rely on systematic reviews to make decisions. It is a common and serious form of research misconduct.
The fix: Frame conclusions according to GRADE certainty. “Moderate-certainty evidence suggests a clinically meaningful reduction in…” is not the same as “X works.” Match your language to your evidence rating.
Mistake 8: Outcome Switching
The error: Changing, adding, or reordering outcomes after seeing the data to emphasize favorable findings.
Why it matters: This is a form of selective reporting that inflates the apparent significance of results. It is detectable by comparing the published review to the registered protocol.
The fix: Pre-specify all primary and secondary outcomes in the PROSPERO registration. If you add or change outcomes after registration, report and justify every change transparently in the manuscript.
Mistake 9: Failing to Complete the PRISMA Checklist
The error: Submitting a manuscript without checking it against the PRISMA 2020 checklist and without including the PRISMA flow diagram.
Why it matters: PRISMA compliance is a submission requirement for most systematic review journals. Missing items result in desk rejection or mandatory major revisions.
The fix: Download the PRISMA 2020 checklist (27 items) from prisma-statement.org. Go through every item before submission. Include the filled checklist as a supplementary file.
Mistake 10: Not Disclosing Conflicts of Interest Completely
The error: Failing to disclose funding sources, prior advocacy positions, or professional relationships that could influence how the review was conducted or interpreted.
Why it matters: Systematic reviews funded by industry sponsors of the intervention being reviewed have been shown to produce more favorable conclusions than independently funded reviews, even when methods appear equivalent. Journals and readers deserve to assess this risk.
The fix: Disclose all funding sources, all reviewer affiliations, and any prior public positions on the topic in a dedicated conflict of interest statement.
Living Systematic Reviews: When Evidence Can’t Wait for a Static Report
A standard systematic review produces a fixed document: a snapshot of the evidence at the time of the search. For clinical questions where new trials publish every few months, a review completed today can be partially outdated by the time it passes peer review.
A living systematic review solves this problem by maintaining a continuously updated version of the review, with surveillance searches run at regular intervals (typically every 6–12 months), new eligible studies incorporated as they are identified, and updated versions published when the evidence changes meaningfully.
When a living SR is appropriate:
- The topic is clinically urgent and a new trial is expected to change conclusions
- Multiple research groups are actively running trials in the area
- Policymakers or guideline developers need continuously current evidence
- The evidence base is sparse but growing rapidly
Structural differences from a standard SR:
- The PROSPERO registration explicitly flags the review as “living”
- A surveillance search schedule is built into the protocol
- Version numbering is used to track updates (v1.0, v1.1, v2.0)
- The published version includes a “last updated” date and a log of changes between versions
- The editorial infrastructure (reviewers, journal) must commit to ongoing updates, not a one-time publication
The Cochrane COVID-19 reviews and several vaccine effectiveness reviews became the most high-profile examples of living systematic reviews during the pandemic, updating monthly as new RCT data emerged.
The honest trade-off: Living SRs require sustained resource commitment for as long as the review remains active. They are not appropriate for stable topics where new evidence is unlikely to change conclusions, or for research teams without the ongoing capacity to screen, extract, and synthesize continuously.
Systematic Reviews Outside Healthcare: Education, Social Science, Business, and Law
Every top result for “systematic review” assumes you are a clinical researcher working in biomedicine. If you are a researcher in education, economics, criminology, environmental science, or legal scholarship, the methodology is broadly the same — but the databases, reporting standards, and community conventions differ significantly.
Education research:
- Databases: ERIC, PsycINFO, JSTOR, Education Source
- Reporting standard: PRISMA (increasingly adopted); What Works Clearinghouse standards for causal evidence
- Key institution: Campbell Collaboration (Education Coordinating Group)
Social science and public policy:
- Databases: PsycINFO, Sociological Abstracts, Social Sciences Citation Index, ProQuest Social Sciences
- Reporting standard: PRISMA; Campbell Collaboration systematic review guidelines
- Key institution: Campbell Collaboration (Crime and Justice, Social Welfare Coordinating Groups)
Environmental science:
- Databases: Web of Science, Scopus, Environment Complete, CAB Abstracts
- Reporting standard: Collaboration for Environmental Evidence (CEE) guidelines — a parallel methodology to Cochrane for environmental questions
- Key institution: Collaboration for Environmental Evidence
Economics and business:
- Databases: EconLit, Business Source Complete, SSRN (for working papers)
- Reporting standard: PRISMA adapted; increasingly, registered reports in top economics journals
- Key difference: Economics reviews more commonly use meta-regression analysis to account for study-level variation
Legal scholarship:
- Databases: HeinOnline, Westlaw, LexisNexis, JSTOR Law
- Key difference: The concept of “risk of bias” in legal scholarship translates into assessment of case representativeness, jurisdiction-specific factors, and interpretive variation
How to Write Up, Submit, and Survive Peer Review
Completing the systematic review is the first challenge. Getting it published is the second — and the one that most guides entirely ignore.
Choosing the Right Journal
Match the journal to the specificity of your topic. The Cochrane Database of Systematic Reviews is the highest-impact dedicated venue, but acceptance requires full adherence to Cochrane methodology. Systematic Reviews (BioMed Central) publishes across all disciplines and is open access. For topic-specific reviews, target the leading journal in your field that regularly publishes methodological work.
Consider impact factor, open-access requirements (particularly if your funder mandates open access), and the journal’s stated scope regarding systematic review methodology. Check whether the journal requires pre-submission protocol registration as a condition of peer review — an increasing number do.
Writing the Methods Section That Survives Peer Review
The methods section of a systematic review is not where you summarize what you did. It is where you prove that what you did was rigorous enough to be trusted. Include:
- Exact search strategies for every database (often as a supplementary appendix)
- The date(s) on which each search was run
- The precise inclusion and exclusion criteria and the rationale for each
- The inter-rater reliability statistics at each screening stage
- The risk of bias tool used and who conducted the assessment
- The statistical methods used for meta-analysis, including the heterogeneity assessment
- The GRADE approach for certainty of evidence
The Seven Most Common Peer Reviewer Criticisms — and How to Pre-Empt Them
- “The search strategy is inadequate” — Pre-empt by including the full search string as a supplementary file, naming every database, reporting the search date, and having a PRESS review conducted by a second librarian before submission.
- “Single reviewer screening was used” — Pre-empt by conducting dual screening and reporting the kappa statistic. If resources truly prevented dual screening, disclose this as a limitation with an explanation.
- “Heterogeneity is not adequately addressed” — Pre-empt by reporting I² for every pooled analysis, conducting subgroup analyses where heterogeneity is moderate or substantial, and explaining in narrative form what the heterogeneity reveals clinically.
- “GRADE is not reported” — Pre-empt by including a GRADE Summary of Findings table as a key results element, not an afterthought.
- “The conclusions exceed what the evidence supports” — Pre-empt by using explicit GRADE language in every conclusion statement: “low-certainty evidence suggests…” rather than “the evidence shows…”
- “Gray literature was not searched” — Pre-empt by documenting every gray literature source searched, the date, and the number of records retrieved.
- “The PRISMA checklist was not completed” — Pre-empt by including the completed PRISMA 2020 checklist as a supplementary file with every submission.
Frequently Asked Questions
What is a systematic review in simple terms?
A systematic review is a research method that finds, evaluates, and synthesizes all available evidence on a specific question using transparent, pre-defined methods. It is different from a regular literature review because every decision — which studies to include, how to assess their quality, how to combine their findings — is made in advance and documented so that other researchers can replicate the process and verify the conclusions.
How long does a systematic review take?
A full systematic review typically takes 12–24 months from protocol registration to publication. The search design phase alone takes 2–6 weeks. Title and abstract screening can take 3–6 months for a large review. Data extraction and quality assessment together add another 2–4 months. Researchers who begin a systematic review expecting to complete it in 3–4 months consistently underestimate the commitment and either produce a substandard review or abandon the project.
What is the difference between a systematic review and a meta-analysis?
A systematic review is the overarching process of identifying, screening, and synthesizing evidence. A meta-analysis is a statistical technique that may or may not be part of a systematic review — it pools quantitative results from multiple studies into a single summary estimate. Not all systematic reviews include a meta-analysis, and not all meta-analyses are preceded by a fully rigorous systematic review (though they should be).
What is PRISMA in a systematic review?
PRISMA (Preferred Reporting Items for Systematic Reviews and Meta-Analyses) is a 27-item reporting standard that specifies the minimum information a systematic review must include to be reproducible and transparent. It includes a flow diagram showing how many records were identified, screened, assessed for eligibility, and ultimately included. Completing the PRISMA checklist and including the flow diagram is a condition of publication in most major journals.
Do I need a team to conduct a systematic review?
Yes. A systematic review requires a minimum of two independent reviewers for all screening and data extraction stages — this is a methodological requirement, not a practical suggestion. Most guidelines recommend a team of at least three (two primary reviewers plus an arbitrator for disagreements). Large reviews often involve teams of five to twelve, including a research librarian and a statistician if meta-analysis is planned.
Can I use AI tools in a systematic review?
Yes, with transparency. AI tools like Elicit, Rayyan, and Consensus can meaningfully accelerate scoping, screening, and data extraction. However, every AI tool used must be named, described, and justified in the methods section. AI screening must be validated against human screening on a sample, and the limitations of AI tools — coverage gaps, potential algorithmic bias — must be acknowledged. AI tools supplement rigorous methodology; they do not replace it.
What is the difference between a systematic review and a scoping review?
A systematic review answers a focused question about the effectiveness of a specific intervention with rigorous quality assessment of included studies. A scoping review maps the breadth of a field — identifying how much evidence exists, what study designs have been used, and where the gaps are — without formally assessing the quality of included studies. Scoping reviews are appropriate when the literature base is heterogeneous and you want to understand its landscape before committing to a full systematic review.
This guide draws on methodology published by the Cochrane Collaboration, the Campbell Collaboration, the EQUATOR Network, and published research methodology literature. It is intended for educational purposes for researchers, students, and evidence practitioners. For clinical guideline development, consult qualified systematic review methodologists and adhere to the standards of the relevant guideline-producing body in your jurisdiction.